애플리케이션의 응답성을 높이고 자원을 효율적으로 사용하기 위해 쓰레드풀에 대해 알아봤다.
웹서버 위에서 동작하는 웹애플리케이션은 리액티브 모델이 아닌 이상 리퀘스트 당 쓰레드를 할당하여 동작한다.
그렇다면 쓰레드를 어떻게 관리하는 것이 좋을까? 쓰레드는 일반적으로 동시에 여러개를 사용하므로 그때그때 생성하여 사용하기 보다는 쓰레드를 미리 생성하여 저장하고, 필요할 때 가져다 쓰고, 사용 후 반납하는 전략을 사용한다. 이러한 풀링 전략은 쓰레드 외에도 Integer의 -127~128 범위와 같은 자주 사용되는 객체를 효율적으로 사용하기 위해 사용되기도 한다.
그렇다면 쓰레드를 효율적으로 관리하기 위해선 "쓰레드풀에 쓰레드를 얼마나 생성하는 것이 좋을까?"에 대해 생각해보아야 한다.
이를 위해선 쓰레드 개수가 적고 많음에 따라 어떤 트레이드오프가 있는지 파악해야 하는데, 우선 JVM에서 사용되는 쓰레드란 무엇인가 알아봤다.

쓰레드는 User Level 쓰레드와 Kernel Level 쓰레드로 구분된다. JVM이 User Level 쓰레드 혹은 combined를 사용한다면, 병렬성을 희생하는 대신 Blocking 상황에서 컨텍스트 스위칭 비용을 아낄 수 있을 것이고, Kernel Level 쓰레드를 사용한다면 병렬성이 뛰어난 대신 시스템 리소스에 의존적일 것이다. 다음 글들을 참고하자.
https://stackoverflow.com/questions/5713142/green-threads-vs-non-green-threads
https://stackoverflow.com/questions/18278425/are-java-threads-created-in-user-space-or-kernel-space
Green Threads vs Non Green Threads
I'd like to understand the advantages provided by these type of threads. In what environments are green threads better than non-green? Some say green threads are better for multi core processors. ...
stackoverflow.com


JVM에서 User Level 쓰레드는 Green Thread라고 한다. 위의 설명과 같이 Kernel Level 쓰레드는 JAVA 쓰레드 객체에 위임하는 구조이며, 더이상 User Level에서 컨텍스트 스위칭을 하지는 않는다고 한다. 따라서 쓰레드풀의 쓰레드개수 == 커널 쓰레드 개수라고 할 수 있다.
*추가: Java spec 상 그린스레드를 허용하지만, 주류 운영환경에선 배제되어 있다. 자바 최적화 한빛미디어 p76)
과연 그럴까? 테스트를 해보자. JAVA11기반의 로컬머신에서 간단히 1000개의 쓰레드를 생성하고 간단한 연산을 하면서 무한루프를 도는 코드를 작성하고, htop을 이용해 시스템을 모니터링해봤다. 참고로 현재 사용중인 로컬머신의 커널쓰레드풀의 최대 쓰레드 수는 약 8000개이다.

테스트 전: 약 2600개의 쓰레드가 생성되어 있다.

테스트 후: 약 3600개의 쓰레드가 생성되어 있다.

추가적으로 1000개의 쓰레드를 생성하는데 걸린 시간은 약 3초, 2000개의 경우 약 20초, 3000개의 경우 약 56초가 걸림을 확인할 수 있었다. 즉 쓰레드 생성 비용은 지수적으로 증가함을 알 수 있다.
정리하자면
1. Java의 쓰레드 생성은 Kernel Level이다. 즉 스위칭 비용이 크다.
2. 쓰레드 생성 비용은 지수적으로 증가한다.
특히 3000개의 쓰레드를 추가적으로 생성했을 경우 스크린샷조차 먹통이었다. 위의 실험에서 도출된 두 개의 결론을 통해 적절한 개수의 쓰레드를 유지하는 풀링 전략이 필요함을 증명할 수 있다.
따라서 응답시간의 꼬리지연을 낮추어 SLO(Service Level Objective)를 준수하기 위해서는 적정 개수의 쓰레드를 유지하고, 프로세스 단위의 Scale Up/Out 등 Scailability를 확보하기 위한 전략이 필요하다.
그렇다면 적정 쓰레드풀의 개수는 어떻게 알 수 있을까? 이론적으로는 Queuing theory의 리틀의 법칙에 따라
쓰레드 수=RPS(Request Per Second)*응답시간(초)로 계산할 수 있다. 혹은 코어 개수에 의존적으로 쓰레드 수 = 사용가능한 코어수*(1+대기시간/서비스시간)으로도 계산할 수 있다고 알려져 있다.
그러나 이론은 이론일 뿐 실제 서비스 환경의 데이터베이스 지연 등 다양한 변수를 고려하지 못한다는 단점이 있다.
따라서 서비스 환경에 맞는 적절한 테스트를 통해 실용적인 쓰레드풀 설정을 하기 위해서는 응답시간을 기준으로 적절한 p50, p99 수준을 정하고, 단일 인스턴스-단일 데이터베이스에서의 측정, 다중 인스턴스-단일 데이터베이스에서의 측정 등 적절한 기준에 맞추어 쓰레드풀 개수를 정하고, 단일 인스턴스의 한계 RPS값에 따라 RPS에 의존적인 스케일링 전략이 필요해보인다.
데이터 중심적인 웹 애플리케이션에서는, 특히 api 콜과 같은 outbound 트래픽이 데이터베이스를 제외하고 없다고 가정한다면 요청 시간의 많은 부분은 데이터베이스 호출시간으로 구성된다. 데이터베이스와 연결을 생성하는 것은 tcp 커넥션으로 이루어지며, tcp 커넥션 비용은 로컬 환경에서의 쓰레드 생성비용보다 훨씬 크다. 따라서 HicariCP와 같은 커넥션 풀을 사용한다.
토이프로젝트로 만든 애플리케이션의 부하테스트와 모니터링 결과 다음과 같은 현상을 관찰할 수 있었다.

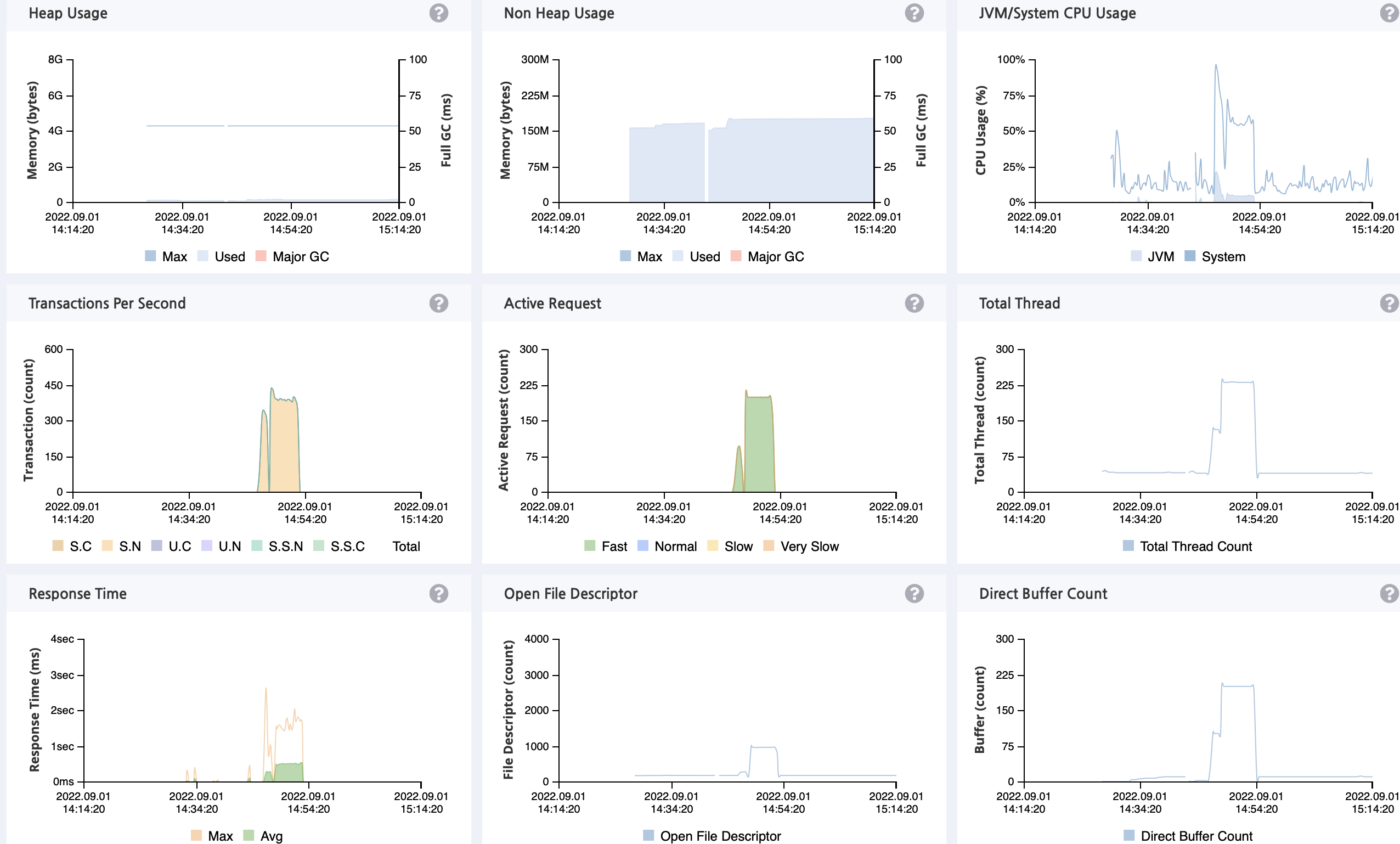
cpu사용량이 낮고, 커넥션을 위한 대기 시간이 긴 케이스이다. 쓰레드풀 크기의 많고 적음의 트레이드오프는 쓰레드풀의 크기가 클 때 모든 요청을 동시적(병렬적와 다른)으로 처리하여 자원의 활용을 높일 수 있다는 장점이 있지만, 시스템의 오버헤드가 크고, 크기가 작다면 동시성이 떨어지지만 시스템의 오버헤드가 작아진다.
이 경우 자원 사용을 효율적으로 사용하지 못하면서 동시성이 떨어지므로 커넥션풀 크기를 키울 필요가 있다. hicariCP의 기본 커넥션풀 개수는 10개이므로 턱없이 부족하다. HicariCp github 문서(https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing)에 소개된 Maximum Pool Size는 다음과 같다.
connections = ((core_count * 2) + effective_spindle_count)
("무려 너무 적어보이는가? 내기해 그럼!" 이라는 표현도 썼다.)
따라서 하이퍼스레딩을 포함해 코어수가 12개인 쿼드코어의 경우 약 25개 내외가 적당하며, 데이터베이스 커넥션 풀도 쓰레드풀과 본질적으론 동일하므로 위에 소개된 쓰레드 수 = 사용가능한 코어수*(1+대기시간/서비스시간) 공식을 사용해 쿼리 실행시간과 애플리케이션 로직 실행 시간을 참고하여 적절하게 튜닝할 수 있다.
테스트를 위해 hicariCP의 커넥션 풀을 30개로 설정하여 테스트한 결과 중 상위 응답시간 백분위를 가지는 결과는 다음과 같다.
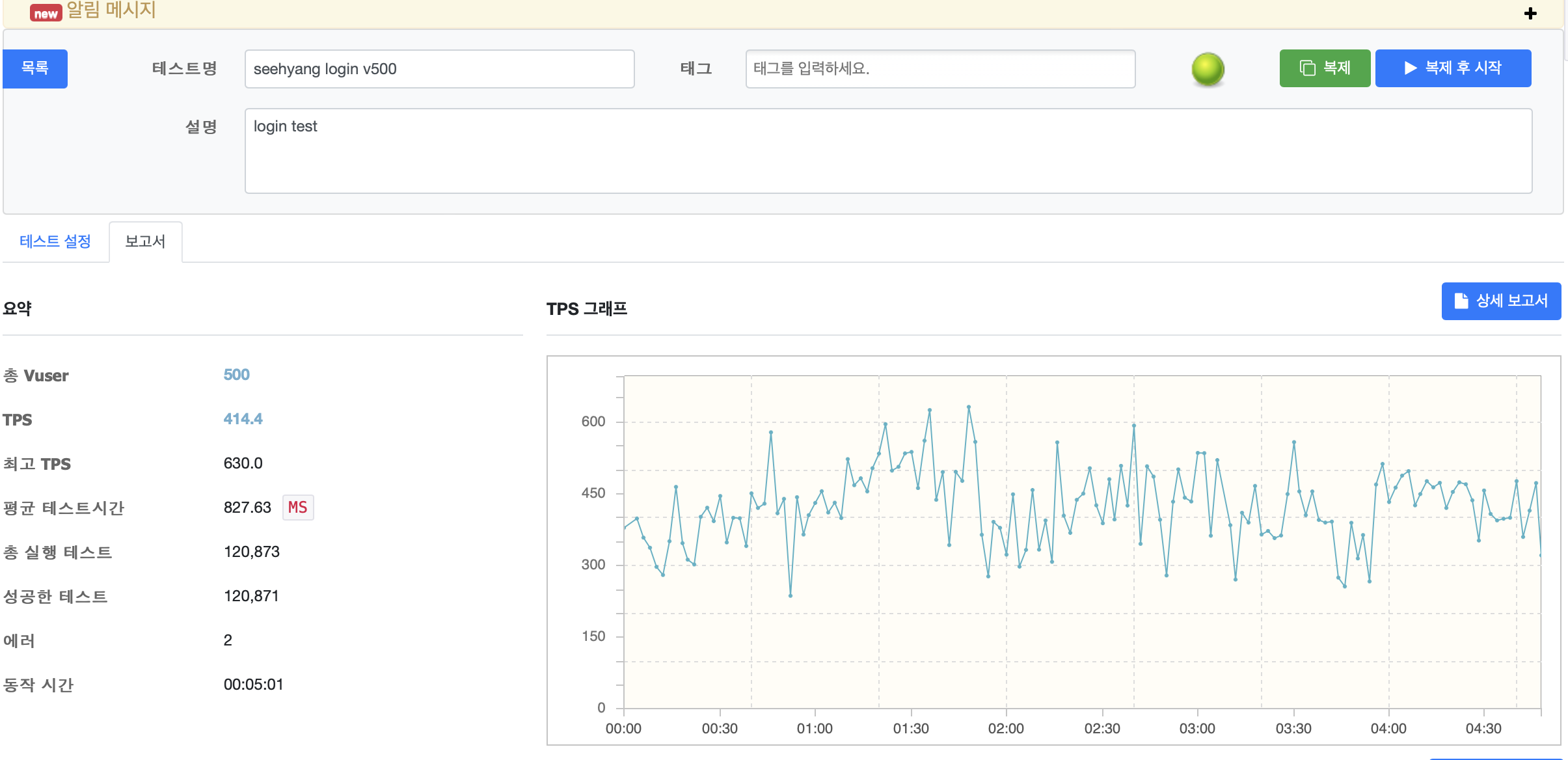
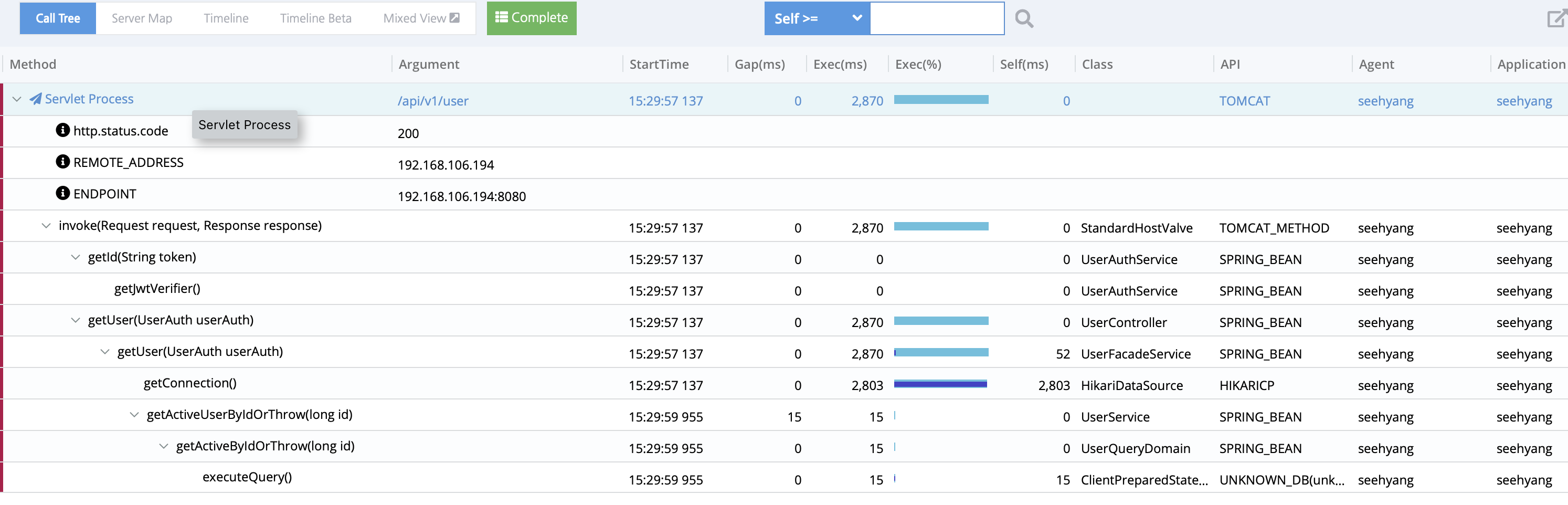
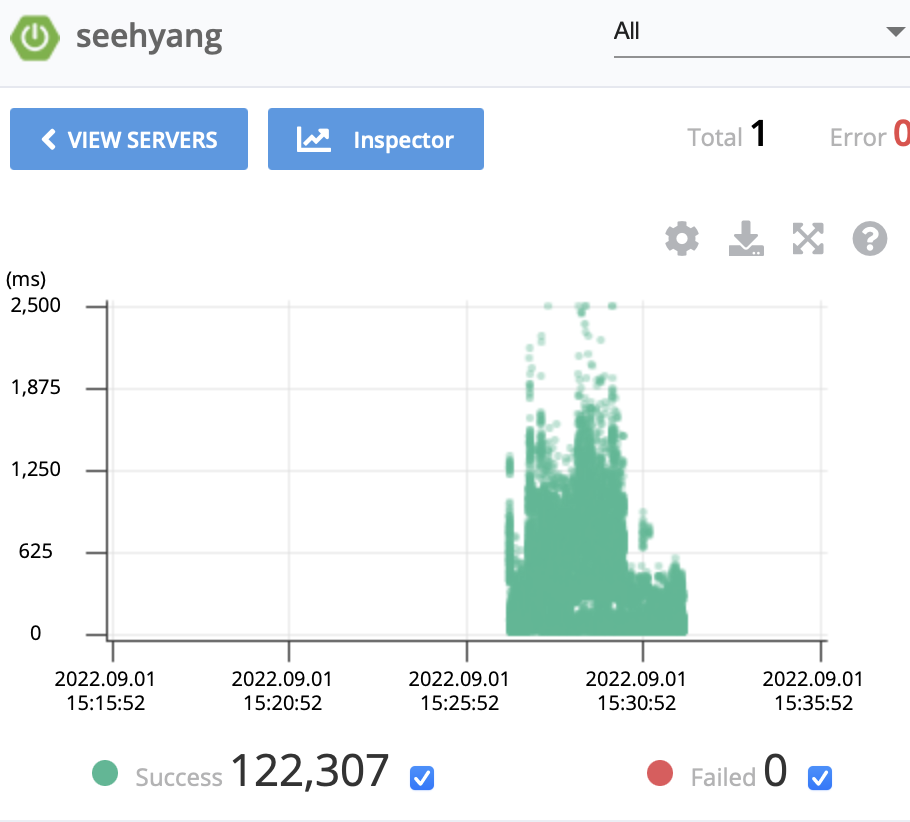
여전히 getConnection() 메서드에서 긴 시간을 소요됨을 알 수 있다. 해당 api의 경우 TPS는 약 410 정도로, 데이터베이스에서 사용자의 정보를 pk(당연히 pk는 인덱싱 되어있다.)를 사용해 단건조회를 하는 api이다. 커넥션풀 사이즈를 100으로 한 다음의 결과를 보자
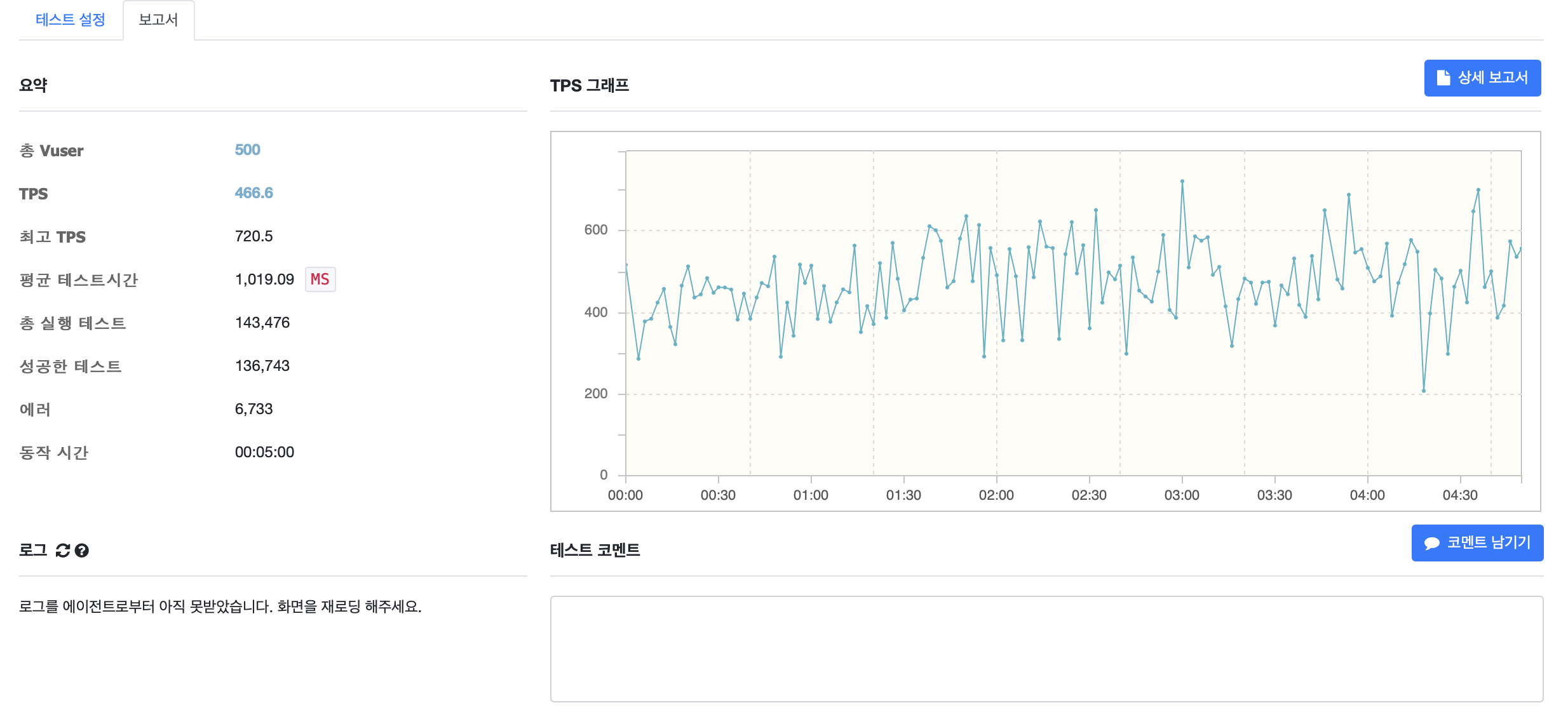
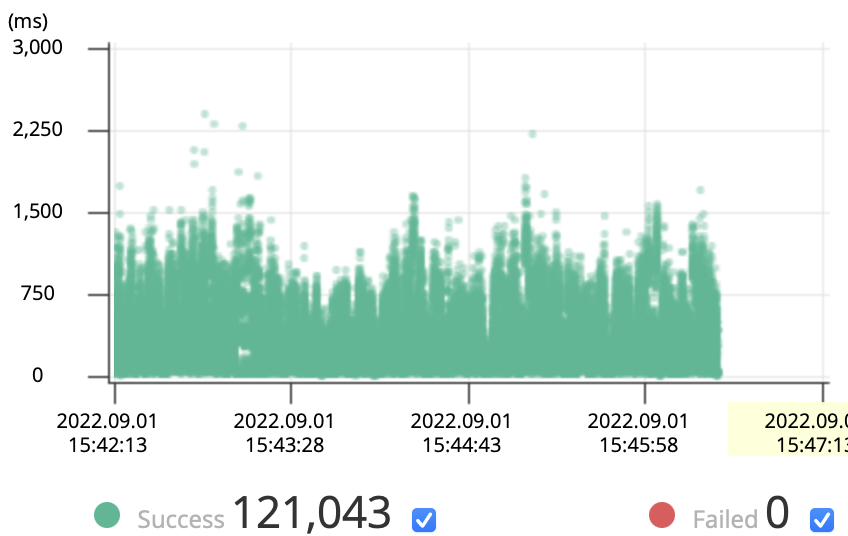
TPS가 460, 최고 TPS또한 720으로 상승한 것을 볼 수 있으며 응답시간또한 비교적 균일해진 모습을 보인다.
테스트를 위해 저장된 약 10만명의 사용자를 조회해오는 시간(대기 시간)과, 단순히 응답객체로 래핑하는 시간(서비스 시간)을 비교해 볼때 쓰레드 수 = 사용가능한 코어수*(1+대기시간/서비스시간) 과 hicariCP에서 권고하는 connections = ((core_count * 2) + effective_spindle_count) 과 타협점을 찾아야함을 알 수 있다.
다만 유의해야 할 점은 부하는 단순히 크다/작다로 판별하는 것이 아닌, 액세스 패턴과 캐시 힛 레이트 등과 같이 부하에 대한 가정사항을 내포한 다차원의 부하 파라미터로 기술되어야 한다. 따라서 하나의 api로만 서비스 시간과 대기시간을 고려해 커넥션 풀의 개수를 정하는 것을 적절하지 않다. 또한 부하 파라미터는 기술적인 측면이 아닌 현재 주력 서비스, 시간대 등으로 결정되므로 경험적인 측면에 의존해야한다.
또한 해당 실험 및 고찰은 반쪽짜리이다. 부하테스트는 반드시 운영시스템에서 해야 의미있는 결과를 도출할 수 있다. 심지어 JVM은 호스트 머신을 파악해서 하드웨어에 적합한 설정을 적용하기도 한다. 로컬피씨에서 수행한 테스트가 얼마나 의미있을 지는 아무도 모른다.
'자바' 카테고리의 다른 글
| BufferedWriter를 Integer와 쓸 때 유의점 (0) | 2021.09.29 |
|---|---|
| 컴파일과 빌드의 차이 (0) | 2021.07.23 |
| 로깅을 어떻게 해야할까? (0) | 2021.07.15 |
| AssertJ - isEqaulTo와 isSameAs의 차이 (0) | 2020.12.29 |



